
Claude Code punching out codes while Gemini lead the way
Combining the "brain" and the "brawn" to produce better and faster working codes - a perfect tag team to solve any programming problems. With actual example from my development process.

This article is also posted on my Medium
Intro
Ever getting into a dead-end circle with you coding agent? You know that moment when the implementation plan is sound, the explanation make sense, your agent rapidly added and updated code changes at places that have very high probability of fixing whatever you are trying to fix, and you think the AI have had it under the belt. Only until you compile the code, hit run and to your disappointment, you find out that the error still persist. “C’mon, five times already.” You thought to yourself.
Sound familiar?
Now at this junction, you have two choices, either you can:
(1) revert to last git commit (if you have one), go back to before the fixing code have been implemented, let the AI know that it’s solution did not work and asking it to “reconsider another approach” and helplessly look at the model punching another heaps of code changes,
(2) go forward and ask the AI “hey, I think your hypothesis (of the root cause) is incorrect, need to do another analysis of the code at here, here, and here…)
Now, whichever choice you made, you (and your model) will still be facing immense uncertainty. You are not sure if you fixing the wrong problem or if you are using the wrong pattern

What you’re doing—and what many junior coders or those without an engineering background tend to do when first trying agent-assisted coding—is essentially deductive reasoning: forming hypotheses and testing them step by step until the root cause of a problem is uncovered. This method is quick, straightforward, and works fine for simple coding issues with only a few possible outcomes.
But when dealing with complex, mature codebase, with hundred thousand lines of code and interconnected modules, scripts, classes, helper function — this approach seemingly lead to finding a needle in a hay stack. The struggle here will be because you are trying to address two moving parts together, the cause and the solution, and your beloved coding agent (Claude Code, Codex, Qwen Coder, etc) will simply cannot handle it.
And do not be fooled by all the hype about “oh, most coding models nowaday can fit more 500,000 or even 1 million tokens — basically fitting entire codebase into it context windows” — sorry but those are mostly marketing speech. Unless a model can actually simulate multiple possible execution paths of your code—like running Monte Carlo–style experiments in real time — which would take dozen of hours even with automated CI pipelines —the size of its context window alone is not the answer.

This issue here is actually more profound than that, it is either due to :
1. Lacking of proper code analysis
2. Lacking of proper code design / structure
3. Lacking of a proper triaging methodology
I will save Point 3 for another article, in this article we shall discuss the solution for Point 1 and 2 altogether.
Lacking of analysis and code design
If you have been a programmer yourself for a years, building actual production-level software that can be used by end-user, you will know how important it is when it come to code design — the foundation structure of your codebase. This is the matter of make or break for your software / application when it come to many vital aspect of a viable application that is usability, scalability, performance, maintenance, security etc.
More importantly, a solid design is a huge advantage when it comes to:
Testing
Debugging
Planning new features
But design alone isn’t enough. For successful execution, it must be paired with proper analysis and documentation that capture essential elements, such as:
The relationships between modules
Abstraction layers
Message queues and data flows
Database design
External frameworks or libraries used
Classes, schemas, and data models
Alternative architectures considered—and the rationale for rejecting them
and many more…
Together design and analysis works like hands in glove. Without both, your AI coder (or even your future self) will just being a know-it-all mice, trapped in a maze — hopping back and forth helplessly between different code modules, files, with no clear direction.

Coding agents are just … so eager
The main problem with many foundation model being fine-tuned for coding task, which I have observed so far, is that is that they always eager to be helpful (or looked helpful) — (with the exception of Gemini 2.5 pro — it maintain a flat, less-than-enthusiastic tone when coding along with me). As such, most models are overly keen to dive straight into whatever part of the code seems problematic at first glance. Worse still, once you suggest a possible root cause or solution, their eagerness often leads them to immediately agree and run with that idea—without critically evaluating whether it’s actually the right fix or not.
Tips: when asking AI coder to triage an issue, do not sound too assertive. Always add into your prompt a little “hint” of uncertainty or hesitation — so that the AI will not “lock in” to a potential pattern or solution which will often lead to tunnel vision issue. For example, you can have the prompt like this “I think the issue is X, but I can be wrong. That “… I can be wrong” phrase will remind the LLM not to fixate on the suggested solution
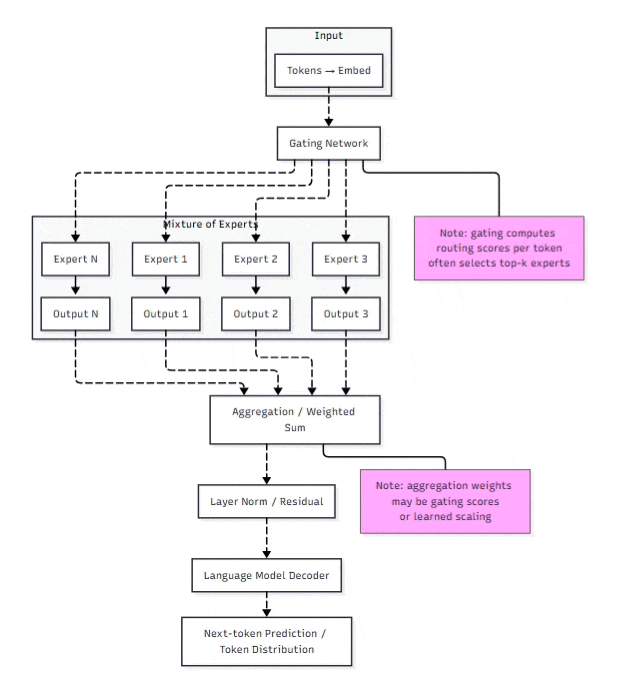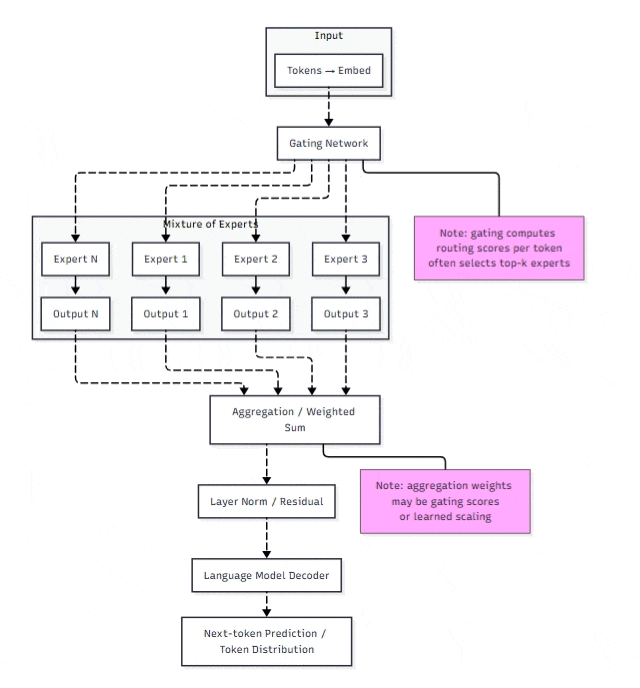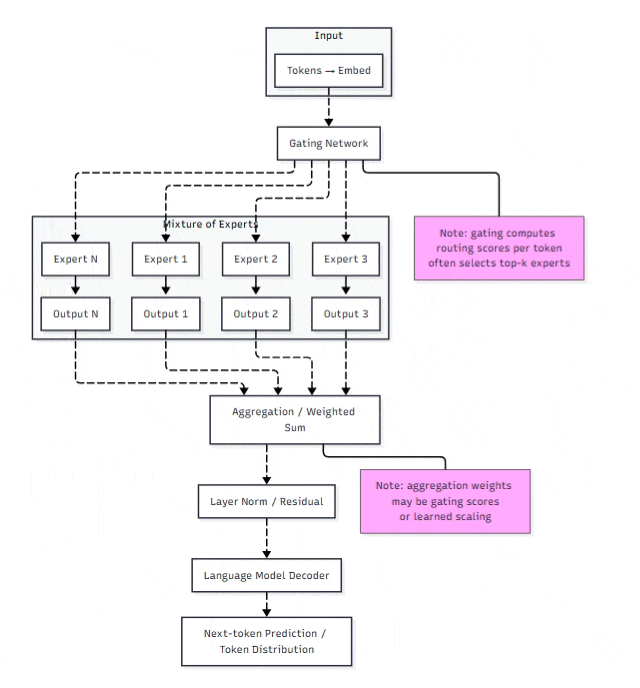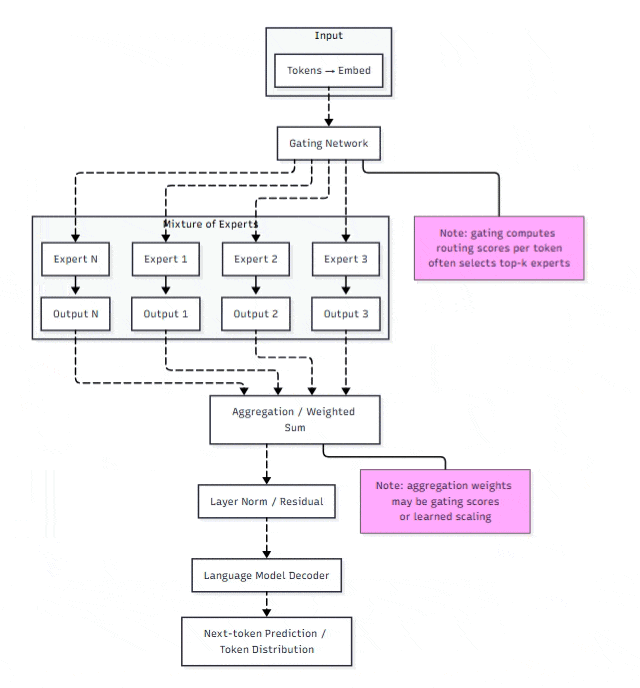
Wait, but then why often you hear or read that coding model are packed with Mixture-of-Expert (MoE) model architecture / transformer variant. So the coding agent should be able to self-critic right?
The answer is Yes and No
What MoE really does: it routes tokens through specialized sub-networks (“experts”), so different parts of a model handle different patterns (e.g., math, reasoning, coding, dialogue). This transformer layer increases breadth of capability but not depth of self-reflection — In other words, the AI model is lack of Self-Checking and simply spitting out auto-regressive token base on pattern in their training dataset, not because it have high probability of solving the root cause (not even mention whether that a correct root cause or not).
Even when fine-tuned with Reinforced Learning with Human Feedback, the signal is post-hoc (final answer judged good/bad), not process-aware (was the reasoning adaptive?). So they can not course-correct mid-stream — they just generate a slightly altered but still a tunnelled continuation.
To frame it in another way, AI coder is good that “coding things right, but not coding the RIGHT thing” — the classic “efficiency-over-effectiveness” story.

So how do we get AI to “code the RIGHT thing” from the get go
Keep reading with a 7-day free trial
Subscribe to Andre’s Substack to keep reading this post and get 7 days of free access to the full post archives.